MIMORE: Microcomparative Morphosyntax Research Tool
SummaryThe MIMORE tool enables researchers to investigate morphosyntactic variation in the Dutch dialects by searching three related databases with a common on-line search engine. The search results can be visualized on geographic maps and exported for statistical analysis. The three databases involved are DynaSAND (the dynamic syntactic atlas of the Dutch dialects), DiDDD (Diversity in Dutch DP Design) and GTRP (Goeman, Taeldeman, van Reenen Project).
Background
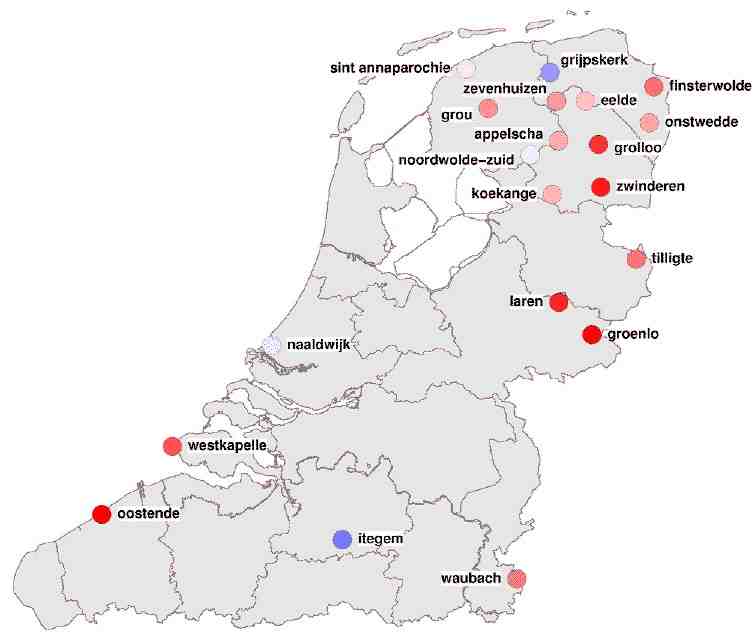
With the MIMORE search engine one can search three databases together, with text strings, part of speech tags and syntactic variables. The researcher can combine categories and features into complex tags or use predefined tags. All categories and features are defined in ISOcat. Since all sentences have a location code, the morphosyntactic phenomena found in a set of sentences resulting from a search can be automatically plotted on a geographic map. It is possible to include more than one morphosyntactic phenomenon in one map, thus visualizing potential correlations between these phenomena. There is also a user-friendly function to export the data to a statistical program.
The data in DynaSAND, the dynamic syntactic atlas of the Dutch dialects (http://www.meertens.knaw.nl/sand/), were collected between 2000 and 2005 by oral interviews (fieldwork and telephone) in about 300 locations across The Netherlands, Belgium and a small part of north-west France. Dialect speakers were asked to judge and/or translate some 150 test sentences. DynaSAND makes available the full recordings and transcriptions of these interviews. Together, the DynSAND data cover the syntactic variation in the Dutch language area in the left periphery of the clause (the complementizer system and complementizer agreement), variation in subject pronoun form depending on syntactic position, subject pronoun doubling, cliticization on YES/NO, the reflexive system, fronting constructions (Wh-clauses, relative clauses, topicalization), word order and morphological variation in verb clusters, negation and quantification.
The data in DiDDD (Diversity in Dutch DP Design; http://www.meertens.knaw.nl/diddd/) were collected between 2005 and 2009 with oral and written interviews in about 200 locations in the Dutch language area, with a methodology highly parallel to DynaSAND. The data involve translations of and judgements on test sentences. For 29 interviews there are sound recordings which have been lined up with their transcriptions. The DIDDD data cover the morphosyntactic variation within nominal groups, in particular possessives, partitives, noun ellipsis, the demonstrative system, the numeral modification system, what-for constructions, quantitative er, adjectival inflection, negation and exclamatives.
The data in GTRP (Goeman, Taeldeman, van Reenen Project; http://www.meertens.knaw.nl/mand/database/) were collected between 1979 and 2000 with oral interviews in about 600 locations in the Dutch language area. Informants were asked to translate words or short sentences. Part of the transcriptions have been lined up with the sound recordings. The morphological data in GTRP include plural forms of nouns, diminutives, gender on nouns and adjectives, comparatives, superlatives, verbal inflection including participles, subject, object and possessive pronouns.
- Project leader: prof. dr. Sjef Barbiers (Meertens Institute & Utrecht University)
- CLARIN center: Meertens Institute
- Help contact : info@meertens.knaw.nl
- Web-sites: http://www.meertens.knaw.nl/mimore/search/
- User scenario's:
- demo powerpoint: http://dev.clarin.nl/sites/default/files/Demo-MIMORE.pdf
- screencast: : http://youtu.be/TBDGrqKYbIA
- Manual: http://www.meertens.knaw.nl/mimore/downloads/documentation.pdf
- Tool/Service link: http://www.meertens.knaw.nl/mimore/search/
- Link to web service: http://www.meertens.knaw.nl/mimore/xmlrpc/
- Link to data sets in Virtual Language Observatory:
- Publications: n.a.