AutoSearch
SummaryAutoSearch allows users to upload corpora annotated at the token level for (extended) part of speech, lemma and word form in FoLiA or
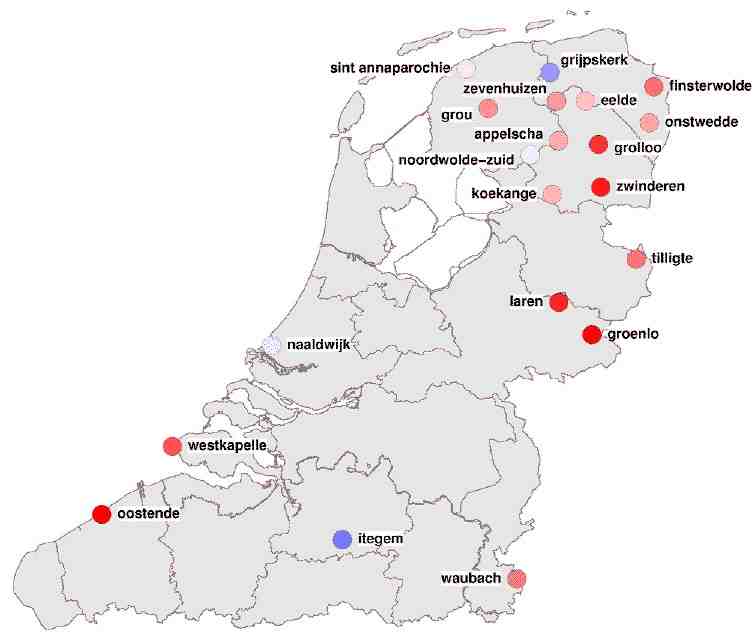
The MIMORE tool enables researchers to investigate morphosyntactic variation in the Dutch dialects by searching three related databases with a common on-line search engine. The three databases involved are also available as XML: DynaSAND (the dynamic syntactic atlas of the Dutch dialects), DiDDD (Diversity in Dutch DP Design) and GTRP (Goeman, Taeldeman, van Reenen Project).
A corpus with data from monolingual and bilingual children (Dutch - Turkish) with and without Specific Language Impairment (SLI).
BackgroundThe FESLI-data come from two NWO-sponsored projects: BiSLI and Variflex. The numbers of children included in the resources are:

OpenSoNaR is an online system that allows for analyzing and searching the large scale Dutch reference corpus SoNaR. Due to the size of the corpus (500 million words), accessing the information contained in the dataset has proven to be difficult for less technically inclined researchers. OpenSoNaR facilitates the use of the SoNaR corpus by providing a user-friendly online interface.
An open access multimedia archive of language pathology data collected in the Netherlands, primarily on Dutch, audio files and transcripts. Currently, this corpus contains 5 different data sets. In the VALID data archive old, current and future data can be brought together.