Title
SummaryThe OpenConvert tools convert to TEI or FOLiA from a number of input formats (alto, text, word, HTML, ePub). The tools are available as a Java command line tool, a web service and a web application.
The OpenConvert tools convert to TEI or FOLiA from a number of input formats (alto, text, word, HTML, ePub). The tools are available as a Java command line tool, a web service and a web application.
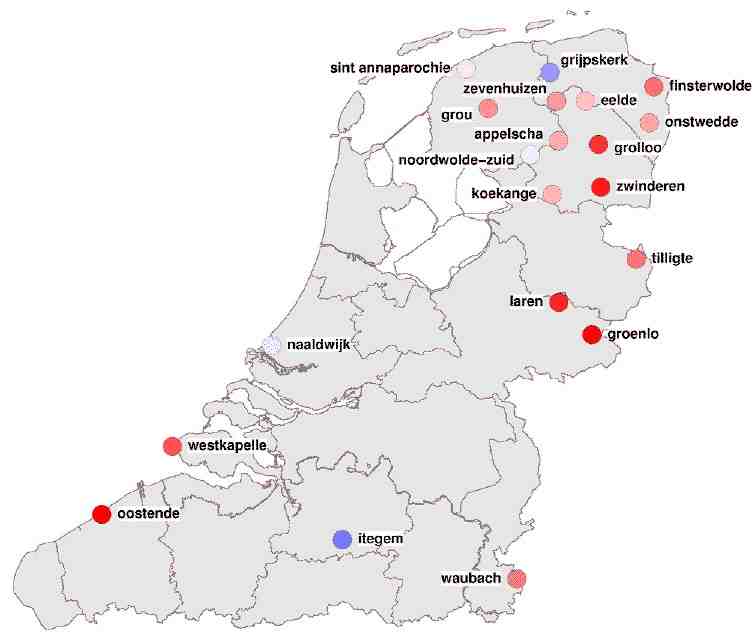
The MIMORE tool enables researchers to investigate morphosyntactic variation in the Dutch dialects by searching three related databases with a common on-line search engine. The three databases involved are also available as XML: DynaSAND (the dynamic syntactic atlas of the Dutch dialects), DiDDD (Diversity in Dutch DP Design) and GTRP (Goeman, Taeldeman, van Reenen Project).

The WIVU Hebrew Text Database contains the Hebrew text of the Old Testament enriched with many linguistic features at the morpheme level up to the discourse level.
A corpus with data from monolingual and bilingual children (Dutch - Turkish) with and without Specific Language Impairment (SLI).
BackgroundThe FESLI-data come from two NWO-sponsored projects: BiSLI and Variflex. The numbers of children included in the resources are: