Nederlab
Nederlab, online laboratory for humanities research on Dutch text collections
SummaryA user-friendly and tool-enriched open access web interface that that aims at containing all digitized texts relevant for the Dutch national heritage and the history of Dutch language and culture (c. 800 - present).
BNM-I
BMN-I: Linked Data on Middle Dutch Sources Kept Worldwide
SummaryWeb application for consultation, using facetted search, and collaborative editing of the curated e-BNM collection of textual, codicological and historical information about thousands of Middle Dutch manuscripts kept world wide.
SHEBANQ

SHEBANQ: System for HEBrew Text: ANnotations for Queries and Markup
SummaryA web application that enables researchers to perform linguistic queries on the WIVU Hebrew Text Database and preserve significant results as annotations to this resource. This database contains the Hebrew text of the Old Testament enriched with many linguistic features at the morpheme level up to the discourse level.
AVResearcherXL
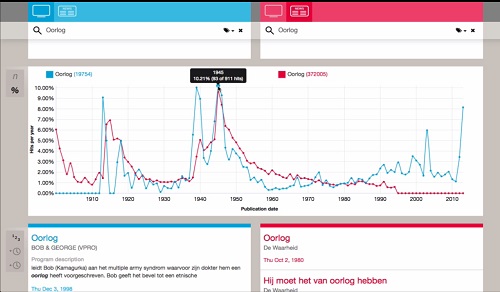
AVReseracherXL: Exploring audiovisual metadata in historical context
SummaryLASSY Word Relations Search
The LASSY word relations web application makes it possible to search for sentences that contain pairs of words between which there is a grammatical relation. One can search in the Dutch LASSY-SMALL Treebank (1 million tokens), in which the syntactic parse of each sentence has been manually verified, and in (a part of) the LASSY-LARGE Treebank (700 million tokens ),in which the syntactic parse of each sentence has been added by the automatic parser Alpino.
CKCC

CKCC - Scholarly Letters
SummaryFESLI
FESLI: Functional elements in Specific Language Impairment
SummaryTool for the quantitative and qualitative comparison of the acquisition of functional elements (morphological inflection, articles, pronouns etcetera) in a corpus with data from monolingual and bilingual children (Dutch - Turkish) with and without Specific Language Impairment (SLI).
MIGMAP
MIGMAP is a web application that can show migration flow between Dutch municipalities. The user first chooses generation (forward or backward in time) and gender, while subsequently the migration map of The Netherlands related to an interactively pointed municipality (or other aggregation unit) is shown.
COAVA
In COAVA two sets of databases are made available in a standardized way: one with historical dialect data (the databases WBD and WLD with lexical data of the Brabantish and Limburgian dialect between 1880-1980) and one with first language acquisition data (four databases form the CHILDES project).
The databases contain linguistic information (dialect form, standardised form (“Dutchified”), lexical meaning), geographical information (locality, dialect area, province) and information on the source (inquiry forms or monotopic dictionaries and the date of documentation). The visualisation of the first two sets of information will lead to lexical maps.
The most typical way for the user to get to the data will be with the use of the browsable concept taxonomy. The databases are, in other words, approachable via search tools but also via a thematic taxonomy. This taxonomy was developed for the dialect databases and covers the general vocabulary.